Some time ago Oracle Cloud Infrastructure introduced features around autoscaling and instance pools. This in short means you have an instance pool which uses image from the instance configuration you have defined. Instance pool has minimum number of instances you want to keep running and with autoscaling you can add scaling out or in depending on metrics like CPU or memory.
You can link the instance pool to a load balancer so if there is a scale out or in event the new instances will be automatically added to load balancer.
So how does it work in practice? I’ve made a Terraform package what you can install and use to create following:
- Public load balancer and a backend set which has instance pool as destination
- Two public subnets for the load balancer and jump server including route table and security list (ports 22 and 80 are open)
- One private subnet for the instance pool instances with route table and security list (ports 22 and 80 are open)
- Instance configuration with standard linux image, instance pool with minimum of two servers, maximum of four servers and autoscaling group which acts when there is certain CPU load on the server
You can download the package for OCI Resource Manager from here.
Creating everything from scratch takes around 10 minutes where instance pool creation is by far the one which takes the longest. Instructions how to use Resource Manager can be seen from my post on creating database in OCI from here.
Remember to add required variables to OCI Resource manager variables for that stack. They are defined in the github README.md.
One Resource Manager related complaint is that while I don’t usually use it is still great for demoing purposes but they should have some kind of version history with zip files you upload so you could see when and what you have previously uploaded and which zip was used on which job.
After the setup has been created successfully you can review either the output on Resource Manager log to see the load balancer and jump server IP or directly check them from console.
Instance configuration
Instance configuration uses latest Oracle Linux 7.6 image as I mention above. It’s standard image what is used for all your instances in the instance pool. One thing to remember when creating the image is that you want your scale out event to be as fast as possible in most cases so make sure booting up the instance normally doesn’t take too long! You need to think what you would have pre-installed in the image and what you can install during bootup.
Testing Instance Pools
First when I had my instance pool up I verified I can see it in the load balancer and health checks are ok. In the instance configuration I’ve used a simple index.html which the load balancer uses for health checks. To do this I’ve used user_data field in Terraform to install httpd server, create the index.html and disabled firewalld. Load balancer part is mainly copied from Oracle’s Terraform load balancer example.
One thing to note is that in normal compute instance the user data is under metadata {} but with instance configuration this is placed under extended_metadata{}.

I also verified that the instance pool shows these instances as healthy under Compute -> Instance Pools:

What I did next is that I just simply terminated one of the instances to see the minimum number of servers (two) would be running. I observed the following:
- After instance switched to terminating it took around 5 minutes until the instance pool marked it as unhealthy and removed it from the instance pool.
- Load balancer marked it as unhealthy during next health check which happened to be 2 minutes after termination (I was using default 300 seconds health check here for backends)
- Once instance pool identified there was one instance missing it took additional 5 minutes until new instance was spawned to the instance pool
I’m not sure how the instance pool health check is monitored and what are the settings for that. So depending on when the instance goes down at the moment it might take ~10-15 minutes to get new instance running which is bit slow in my opinion at this point.
After instance was provisioned the new instance was automatically added to the load balancer and all traffic immediately got routed also through load balancer to the new instance.
Autoscaling
Next I was ready to to test autoscaling. I’ve defined a very low scaling policy in my Terraform setup. If the CPU load is greater than 10% there will be a scale out event and if it’s less than 10% it will scale in. In both cases autoscaling will add or remove just one server.
To test this I installed linux utility “stress” in the instance pool instances which you can see in the user-data variable in variables.tf. To get CPU load going higher I ran the command stress -c 2 on one of the auto scaling instances and verified CPU load was high through the instance monitoring page. To login to instance pool instances you need to use the jump server in between and use same ssh key as for the jump server.
After some minutes I could see instance pool changed to scaling and it was adding an instance.

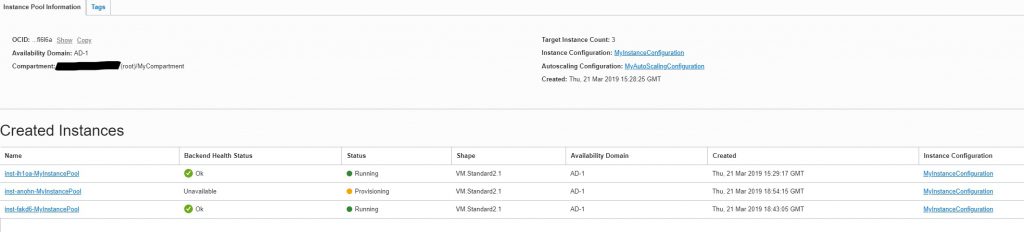
In the instance pools I can see new instance being provisioned
I could also observe that right away the instance got added to backend servers on the load balancer.
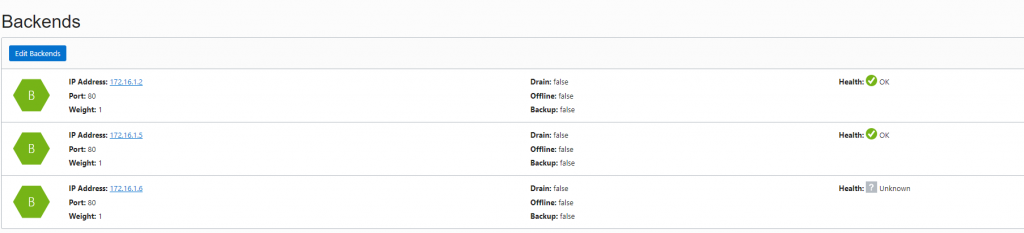
I left stress running on the same server and after the 300 seconds I observed another scale out event and autoscaling added a fourth server. I think this would need further definition. How is the scale out value of CPU greater than X counted. Is it overall from all the servers? If CPU is 100% on one server and 0% on two others is it counted as 33%?
After completing the test I just stopped running stress and after the five minute cooldown period auto scaling did a scale in event and removed one of the servers. After another cooldown period it removed the third server and I was back to original two servers. Note that at this point in time the autoscaling minimum cooldown period is 300 seconds and it can not be set lower. I would believe they will improve it in the future as waiting five minutes might be too long for some configurations specially when the scaling event seems to take additional time.
Also there is no definition what is the rule when scale in happens. Which server gets terminated first (seems like the oldest) but what if I have servers in multiple Availability Domains and their number is not even etc. With AWS you have this clearly defined so hoping they would do a similar update in documentation.
UPDATE: I got information that the rule is to balance Availability Domains first (just like AWS) and then terminate the oldest. Also this should be coming up to the official documentation as well.
I still wanted to test how scale out is counted so I changed the scaling policy to scale out whenever CPU load is greater than 49% with two servers initially in the instance pool. So if CPU is 100% on one server with two servers in instance pool it would mean 50% (scale out) and with three servers it would mean 33% (scale in). And this is exactly what happened!
First I saw scale out event and after the cool down period I saw a scale in event. This could be defined more clearly in the documentation as well.
Summary
There is lot of potential with OCI autoscaling as earlier you didn’t have such functionality with OCI compared to some other cloud providers such as AWS for example. Creating the instance configuration, instance pool and auto scaling group is really simple and you get things set up quickly. However the autoscaling events still take long time, I’d like to get new image running faster compared to 10-15 minutes I saw during my testing.
The recent addition to spawn subnet across Availability Domains is great for autoscaling. Think when you can create only one subnet and autoscaling keeps your instances in one subnet balanced automatically.
As this is still new service in OCI I imagine they will improve it a lot in the next months. At this point in time I see some missing details in documentation like the termination (should be coming up!) and scale in/out rules. Also when there is a scale in/out event it would be nice if I could get a notification on it as otherwise you don’t really know if there are events happening. This is a feature also coming up I was told which is great.
What if you want to update your instance configuration with a new image? In AWS this means you will need to create a new launch configuration and assign it to your auto scaling group. Right now in OCI it’s not possible from Terraform or Console but it’s exposed via API only. So definitely a feature which is coming up to be used from everywhere!
There is also really good example from Oracle on autoscaling e-Business Suite instances to show potential what you can do it. While there is definitely case to scale eBS on CPU I think functionality such as scheduled scaling would benefit eBS more depending how fast scaling out one node takes. But from the example you see even legacy systems can benefit from cloud functionalities!
In closing remarks I have to say I’m really impressed in people working for Oracle providing help and further clarify things on OCI functionality. They are definitely keen on building a solid cloud offering which hopefully people will adapt in the future more and more.
[…] time ago I published a post where I took a test drive with OCI Autoscaling. Now after an eventful summer I think it’s time to retest Autoscaling mainly due to some […]
OCI autoscaling is a tiny cloud hamster on a wheel.
Is it working? Yes.
Is it stressed? Also yes.” ?☁️